To adapt to my learning style at least the number for easy (4) should be an optimizable parameter. For learning styles like mine that would allow the difficulty to decrease faster when Easy is selected than it increases when Again or Hard is selected.
As far as I understand, this could allow the optimization to solve this problem:
For me the difficulty for difficult cards rises in the learning phase as it should, but when entering the review phase this is a problem, b/c the review intervals become way too short and selecting Easy lowers the difficulty much to slow. Once these difficult cards make it into my memory for a day, they become much easier for me and the intervals on “Easy” should become much longer much faster.
I’ve tried lots of different modifications of the formula for D. Almost none (except for one) improved metrics, and that one improved metrics by like 1%.
Optimizable grades (instead of Again=1, Hard=2, etc.) were one of the first things me and Jarrett tried all the way back in FSRS v4 days, and they didn’t improve metrics. D is kinda cursed for some reason.
EDIT: btw, I’m working on FSRS-7 which will handle same-day reviews properly.
Do you know how this prediction improvement was distributed among the users? For example, did most users get a 1% improvement, or did maybe 5% of users get a 20% improvement?
I would argue that only the parameters for which this “improvement distribution” has been checked should be discarded. If this check is difficult, why not just introduce the parameter when in doubt? Are the costs of a new parameter high?
If the improvements are unevenly distributed, there would be a group of users whose prediction improvements from a parameter could be much higher than the average improvement. With millions of users, even a tiny percentage would mean helping a large absolute number of users.
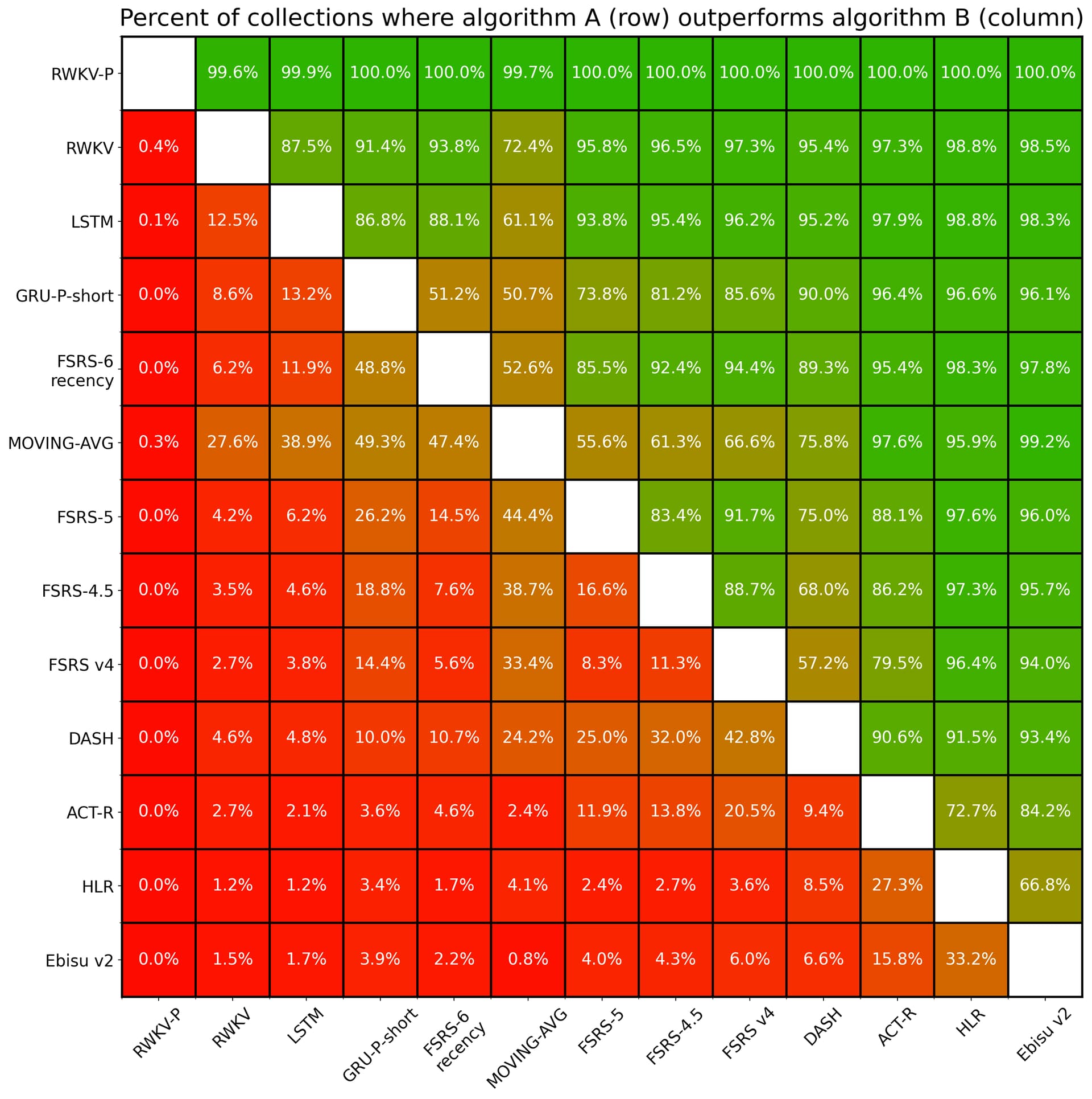
When we release a new version of FSRS, we always make sure that it’s better for >=51% of users, in the sense that if there is FSRS-X and FSRS-(X+1), FSRS-(X+1) should have lower logloss (a measure of how well the algorithm is predicting the probability of recall) for at least 51% of users in the 10k dataset.
For example, FSRS-6 with recency weighting (adapting more to newer reviews and less to older reviews) outperforms FSRS-5 for 85.5% of users. Of course, we also check that the average logloss is better, to avoid a situation where a new version is slightly better for a lot of people but significantly worse for a few.
Out of curiosity I tried optimizable grades again, with my unreleased FSRS-7.
Nope, still doesn’t make metrics better. @chrislg idk. I’ve made good progress, but right now I’m kinda out of ideas on how to improve it. It should be done by the end of the year, if I had to guess. @Danika_Dakika as I’ve said on Discord, I have a working version. The issue, as I explained, is that while it’s very clearly better than FSRS-6 on all reviews (same-day + non-same-day), it’s worse than FSRS-6 on non-same-day reviews. So I still need to work on it, but it’s definitely more done than “ideas on the drawing board”.
I didn’t mean to suggest you weren’t working on it. But it’s a goal – to improve same-day/step scheduling – that you haven’t figured out how to reach yet without a downside, and you don’t have ideas about what else to try. I think folks are getting confused by hearing it touted as “FSRS-7: Coming Soon!”
I guess I need to be more precise. It’s a lot more likely that FSRS-7 will be finished by the end of the year (or at worst in early 2026) than by 2027 or 2028 or whatever. It’s not years away.