Especially when paired with FSRS-6, CMRR is practically useless. It almost always gives 70% as output and users can’t choose DR below 70% anyway. @Expertium has tried various methods to produce higher values, without much success.
However, a more important issue is that it gives just a single value, which isn’t helpful for users who want to decide what DR value will give them the best compromise between retention and workload based on their priorities. Some users may want high retention despite higher workload. Others may want low workload despite lower retention.
I think the best way is providing them with a graph so they can know how their workload will increase/decrease with DR changes. The new “Approximate workload: 1.05x” feature is good, but not really helpful in choosing DR because it shows the value for only one DR at a time and users must note down values for different DRs to analyze them properly.
So, I think we should replace CMRR with a new button saying something like “Plot a graph showing workload against desired retention (slow)”.
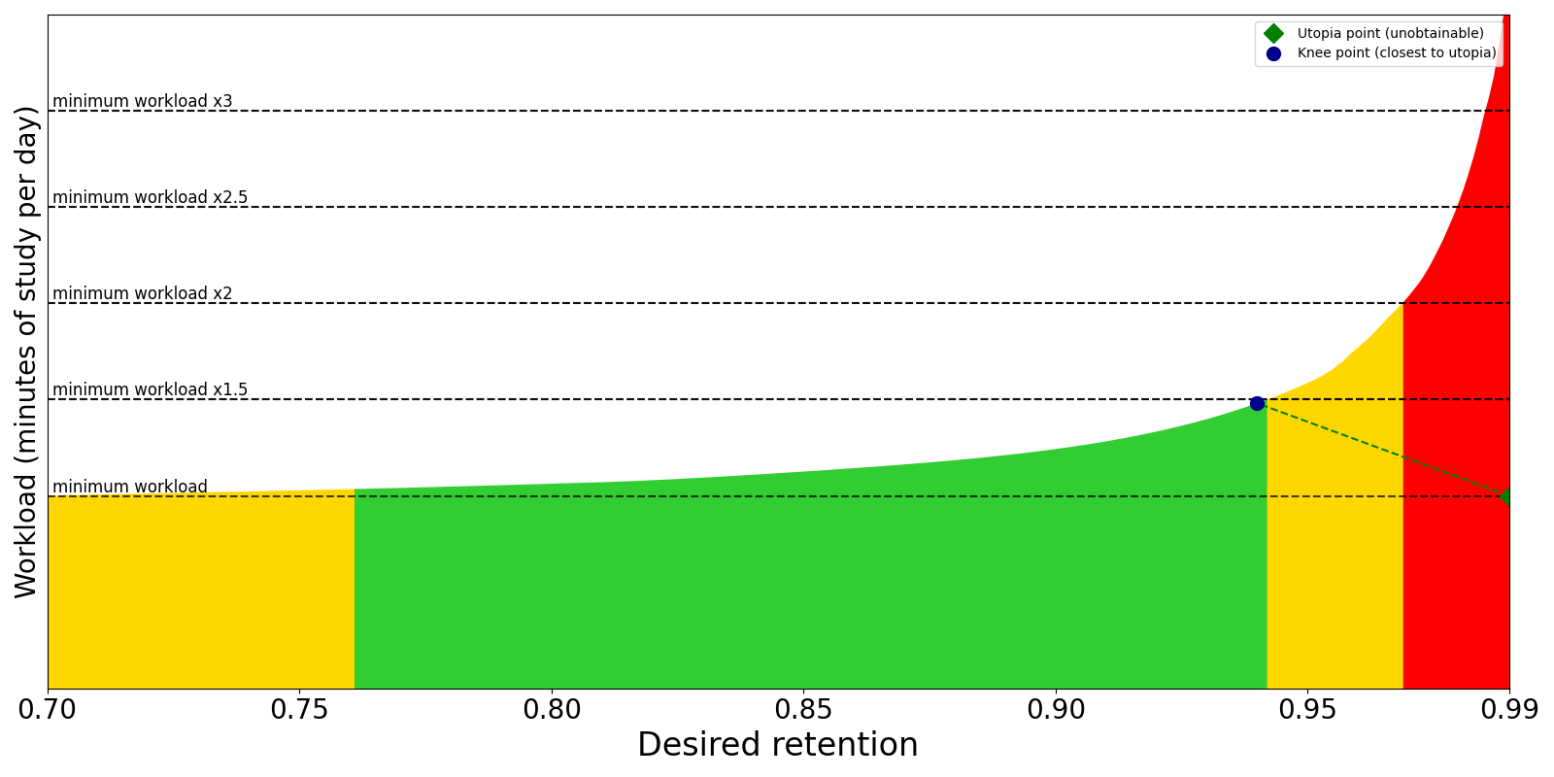
Additionally, even though we want users to choose a DR value that best fulfills their needs, many users will have difficulty choosing when presented with a graph like the following because no point immediately stands out.

So, we should provide users with a starting value. The easiest solution is the “knee point” — the point on the Pareto frontier with maximum curvature, where small improvements in one objective require large sacrifices in the other.
(@Expertium surely has code to calculate this.)
However, the knee point is just a geometric heuristic that ignores what the user actually cares about. There’s a way to calculate a more personalized DR value but that’s more involved. If implemented, we wouldn’t need to plot the graph. Just use workload vs DR values and user responses to give them a personalized DR value.
Though quite complicated, I’ll describe it, in case it interests anyone. (Most content below is AI-generated.)
The Robust MAUT approach is the best way to choose a DR value that balances retention and workload based on personal preferences.
The first step is choosing the relative importance of retention and workload, which is the fundamental challenge in multi-objective optimization. This is actually well-studied, and there are several mathematically principled ways to elicit weights that are superior to manual graph analysis. (see implementation below)
Why are these methods better than manual graph analysis?
- Cognitive science backing: These methods account for known human biases
- Consistency checking: Catches and corrects logical inconsistencies
- Statistical rigor: Provides confidence intervals on your preferences
- Adaptive: Gets more accurate with more questions
- Validation: Tests whether the weights actually predict your choices
Time investment: 10-15 minutes once vs. endless graph staring
Accuracy: Mathematically proven to be more reliable than visual estimation
Working Python code for Robust MAUT approach (AI-generated)
This code works but the actual calculated values of DR and minutes/day should be used in place of the placeholder values. Plus, the questions used to elicit the weights probably need fine-tuning.
Also, instead of DR vs minutes, we should probably use total knowledge vs minutes because that’s easier to answer in the questions this script asks.
import numpy as np
from scipy.optimize import minimize, minimize_scalar, curve_fit
from scipy.interpolate import interp1d
import matplotlib.pyplot as plt
from typing import List, Tuple, Dict, Any
class DROptimizer:
def __init__(self, dr_values, time_values):
"""Initialize with your DR vs time data
Args:
dr_values: List of DR percentages [70, 73, 76, ...]
time_values: List of corresponding minutes [19.8, 22.6, 26.2, ...]"""
self.dr_values = np.array(dr_values) / 100.0 # Convert to decimal
self.time_values = np.array(time_values)
# Create interpolation function for smooth optimization
self.time_function = interp1d(self.dr_values, self.time_values,
kind='cubic', fill_value='extrapolate')
# Fit analytical model for better understanding
self.fit_time_model()
def fit_time_model(self):
"""Fit an analytical model: time = a * DR^b / (1-DR)^c
This captures the exponential growth as DR approaches 1"""
def model(dr, a, b, c):
return a * (dr ** b) / ((1 - dr) ** c)
try:
# Initial guess
p0 = [1.0, 2.0, 1.0]
self.model_params, _ = curve_fit(model, self.dr_values, self.time_values, p0=p0)
self.analytical_model = lambda dr: model(dr, *self.model_params)
print(f"Fitted model: time = {self.model_params[0]:.2f} * DR^{self.model_params[1]:.2f} / (1-DR)^{self.model_params[2]:.2f}")
except Exception:
# Fallback to interpolation only
self.analytical_model = self.time_function
print("Using interpolation model")
def get_time_for_dr(self, dr):
"""Get time in minutes for a given DR"""
if hasattr(self, 'analytical_model'):
return self.analytical_model(dr)
else:
return self.time_function(dr)
def utility_retention(self, retention):
"""Utility function for retention - linear since weight is very low"""
# Simple linear utility since your retention weight is very low (0.010)
return retention
def utility_time(self, time_minutes):
"""Utility function for time (negative because time is a cost)
Since your time weight is very high (0.990), time dominates"""
# Linear disutility for time (negative)
return -time_minutes
def overall_utility(self, dr, w_retention, w_time):
"""Calculate overall utility for a given DR"""
retention = dr
time_minutes = self.get_time_for_dr(dr)
u_retention = self.utility_retention(retention)
u_time = self.utility_time(time_minutes)
return w_retention * u_retention + w_time * u_time
def robust_maut_optimization(self, w_retention, w_time,
retention_uncertainty=0.02,
time_uncertainty=0.1,
n_samples=1000):
"""Robust MAUT optimization with uncertainty"""
def robust_utility(dr):
utilities = []
for _ in range(n_samples):
# Sample uncertain retention (e.g., measurement error)
actual_retention = dr + np.random.normal(0, retention_uncertainty)
actual_retention = np.clip(actual_retention, 0.01, 0.99)
# Sample uncertain time (multiplicative uncertainty)
time_base = self.get_time_for_dr(dr)
time_multiplier = np.random.lognormal(0, time_uncertainty)
actual_time = time_base * time_multiplier
# Calculate utility for this sample
u_retention = self.utility_retention(actual_retention)
u_time = self.utility_time(actual_time)
utility = w_retention * u_retention + w_time * u_time
utilities.append(utility)
# Return 10th percentile (robust statistic)
return np.percentile(utilities, 10)
# Optimize over the DR range
result = minimize_scalar(
lambda dr: -robust_utility(dr), # Negative for maximization
bounds=(self.dr_values.min(), self.dr_values.max()),
method='bounded')
optimal_dr = result.x
optimal_utility = -result.fun
return optimal_dr, optimal_utility
def simple_optimization(self, w_retention, w_time):
"""Simple optimization without uncertainty"""
def objective(dr):
return -self.overall_utility(dr, w_retention, w_time)
result = minimize_scalar(
objective,
bounds=(self.dr_values.min(), self.dr_values.max()),
method='bounded')
return result.x, -result.fun
def analyze_tradeoffs(self, w_retention, w_time):
"""Analyze the utility across all DR values"""
dr_range = np.linspace(self.dr_values.min(), self.dr_values.max(), 100)
utilities = [self.overall_utility(dr, w_retention, w_time) for dr in dr_range]
times = [self.get_time_for_dr(dr) for dr in dr_range]
return dr_range, utilities, times
def plot_analysis(self, w_retention, w_time, optimal_dr):
"""Create visualization of the optimization"""
dr_range, utilities, times = self.analyze_tradeoffs(w_retention, w_time)
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(10, 12))
# Plot 1: DR vs Time (your data)
ax1.scatter(self.dr_values * 100, self.time_values, color='red', s=50, label='Your data')
ax1.plot(dr_range * 100, times, 'b-', label='Fitted model')
ax1.axvline(optimal_dr * 100, color='green', linestyle='--', label=f'Optimal DR = {optimal_dr*100:.1f}%')
ax1.set_xlabel('Desired Retention (%)')
ax1.set_ylabel('Time (minutes/day)')
ax1.set_title('DR vs Time Relationship')
ax1.legend()
ax1.grid(True, alpha=0.3)
# Plot 2: DR vs Utility
ax2.plot(dr_range * 100, utilities, 'purple', linewidth=2)
ax2.axvline(optimal_dr * 100, color='green', linestyle='--', label=f'Optimal DR = {optimal_dr*100:.1f}%')
optimal_utility = self.overall_utility(optimal_dr, w_retention, w_time)
ax2.axhline(optimal_utility, color='green', linestyle=':', alpha=0.7)
ax2.set_xlabel('Desired Retention (%)')
ax2.set_ylabel('Utility')
ax2.set_title('Utility Function (Higher is Better)')
ax2.legend()
ax2.grid(True, alpha=0.3)
# Plot 3: Marginal analysis
marginal_utility = np.gradient(utilities, dr_range)
ax3.plot(dr_range[1:] * 100, marginal_utility[1:], 'orange', linewidth=2)
ax3.axhline(0, color='black', linestyle='-', alpha=0.5)
ax3.axvline(optimal_dr * 100, color='green', linestyle='--', label=f'Optimal DR = {optimal_dr*100:.1f}%')
ax3.set_xlabel('Desired Retention (%)')
ax3.set_ylabel('Marginal Utility')
ax3.set_title('Marginal Utility (Optimal where = 0)')
ax3.legend()
ax3.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
return fig
class AnkiWeightElicitor:
def __init__(self):
self.questions_asked = []
self.responses = []
def ask_human(self, question: Dict[str, Any]) -> str:
"""Present question to human and get response"""
if question['type'] == 'pairwise':
print("\nWhich scenario do you prefer?")
print(f"A: {question['option_a']['retention']*100:.1f}% retention, {question['option_a']['time_minutes']:.1f} min/day")
print(f"B: {question['option_b']['retention']*100:.1f}% retention, {question['option_b']['time_minutes']:.1f} min/day")
while True:
choice = input("Enter A or B: ").upper().strip()
if choice in ['A', 'B']:
return choice
print("Please enter A or B")
elif question['type'] == 'validation':
print("\nValidation question:")
print(f"A: {question['option_a']['retention']*100:.1f}% retention, {question['option_a']['time_minutes']:.1f} min/day")
print(f"B: {question['option_b']['retention']*100:.1f}% retention, {question['option_b']['time_minutes']:.1f} min/day")
while True:
choice = input("Which do you prefer? (A/B): ").upper().strip()
if choice in ['A', 'B']:
return choice
print("Please enter A or B")
elif question['type'] == 'tradeoff':
print(f"\n{question['question']}")
while True:
try:
answer = float(input("Your answer: "))
if question.get('min_value', 0) <= answer <= question.get('max_value', 100):
return str(answer)
print(f"Please enter a value between {question.get('min_value', 0)} and {question.get('max_value', 100)}")
except ValueError:
print("Please enter a number")
def calculate_weights_from_tradeoffs(self, answers: List[float]) -> Tuple[float, float]:
"""Calculate weights from direct trade-off questions"""
# Question 1: "What's the minimum retention you'd accept to reduce time from 25 to 20 min/day?"
# If answer is 85%, then 5% retention loss = 5 min gain
# So w_retention/w_time = 5 min / 5% = 1 min per percentage point
retention_loss_q1 = 90 - answers[0] # Loss in retention percentage
time_gain_q1 = 5 # Minutes saved
ratio_1 = time_gain_q1 / max(retention_loss_q1, 0.1) # w_time / w_retention
# Question 2: "What's the maximum time you'd spend to increase retention from 90% to 95%?"
# If answer is 35 min/day, then 5% retention gain = 10 min cost
retention_gain_q2 = 5 # Percentage points
time_cost_q2 = answers[1] - 25 # Additional minutes
ratio_2 = max(time_cost_q2, 0.1) / retention_gain_q2 # w_time / w_retention
# Question 3: Indifference point
# 90% at 25 min = X% at 15 min
# w_retention * 90 - w_time * 25 = w_retention * X - w_time * 15
# w_retention * (90 - X) = w_time * (25 - 15)
# w_time / w_retention = (90 - X) / 10
retention_indiff_q3 = answers[2]
ratio_3 = (90 - retention_indiff_q3) / 10
# Average the ratios (with some robustness)
ratios = [r for r in [ratio_1, ratio_2, ratio_3] if 0.01 <= r <= 100]
avg_ratio = np.median(ratios) if ratios else 1.0
# Convert to normalized weights
w_time = avg_ratio / (1 + avg_ratio)
w_retention = 1 / (1 + avg_ratio)
return w_retention, w_time
def generate_validation_scenario(self) -> Dict[str, Any]:
"""Generate a validation question not used in elicitation"""
scenarios = [
{"retention": 0.88, "time_minutes": 18},
{"retention": 0.93, "time_minutes": 28},
{"retention": 0.86, "time_minutes": 16},
{"retention": 0.94, "time_minutes": 32}]
# Pick two scenarios randomly
import random
option_a, option_b = random.sample(scenarios, 2)
return {
'type': 'validation',
'option_a': option_a,
'option_b': option_b}
def predict_choice(self, question: Dict[str, Any], weights: Tuple[float, float]) -> str:
"""Predict human choice based on utility weights"""
w_retention, w_time = weights
# Calculate utilities (normalize time to same scale as retention)
utility_a = w_retention * question['option_a']['retention'] - w_time * (question['option_a']['time_minutes'] / 60)
utility_b = w_retention * question['option_b']['retention'] - w_time * (question['option_b']['time_minutes'] / 60)
return 'A' if utility_a > utility_b else 'B'
def resolve_inconsistencies(self) -> Tuple[float, float]:
"""Resolve inconsistencies through focused questions"""
print("\nI detected some inconsistencies in your responses.")
print("Let me ask a few clarifying questions...")
# Ask clarifying questions focusing on the biggest inconsistencies
clarifying_questions = [
{
'type': 'pairwise',
'option_a': {'retention': 0.90, 'time_minutes': 25},
'option_b': {'retention': 0.85, 'time_minutes': 15}
},
{
'type': 'pairwise',
'option_a': {'retention': 0.95, 'time_minutes': 35},
'option_b': {'retention': 0.90, 'time_minutes': 25}
}]
responses = []
for q in clarifying_questions:
response = self.ask_human(q)
responses.append((q, response))
# Fit weights to these clearer preferences
return self.fit_utility_weights_from_pairwise(responses)
def refine_weights(self, current_weights: Tuple[float, float],
validation_question: Dict[str, Any],
actual_choice: str) -> Tuple[float, float]:
"""Refine weights based on validation feedback"""
w_ret, w_time = current_weights
# Calculate what the weights should be to predict the actual choice
option_a = validation_question['option_a']
option_b = validation_question['option_b']
# If actual choice was A, then utility_a should > utility_b
# w_ret * ret_a - w_time * time_a/60 > w_ret * ret_b - w_time * time_b/60
# w_ret * (ret_a - ret_b) > w_time * (time_a - time_b)/60
ret_diff = option_a['retention'] - option_b['retention']
time_diff = (option_a['time_minutes'] - option_b['time_minutes']) / 60
if actual_choice == 'A':
# Need w_ret * ret_diff > w_time * time_diff
if ret_diff != 0:
min_ratio = time_diff / ret_diff if ret_diff > 0 else float('inf')
# Adjust weights to satisfy this constraint
if w_time / w_ret <= min_ratio:
# Current weights are consistent, small adjustment
adjustment = 0.1
else:
# Need bigger adjustment
adjustment = 0.3
else:
adjustment = 0.1
else: # actual_choice == 'B'
# Need w_ret * ret_diff < w_time * time_diff
if ret_diff != 0:
max_ratio = time_diff / ret_diff if ret_diff > 0 else 0
if w_time / w_ret >= max_ratio:
adjustment = 0.1
else:
adjustment = 0.3
else:
adjustment = 0.1
# Apply adjustment
if actual_choice == 'A':
# Increase retention weight
w_ret_new = min(0.95, w_ret + adjustment * (1 - w_ret))
w_time_new = 1 - w_ret_new
else:
# Increase time weight
w_time_new = min(0.95, w_time + adjustment * (1 - w_time))
w_ret_new = 1 - w_time_new
return w_ret_new, w_time_new
def fit_utility_weights_from_pairwise(self, comparisons: List[Tuple]) -> Tuple[float, float]:
"""Fit utility weights from pairwise comparisons"""
def objective(weights):
w_retention, w_time = weights
error = 0
for question, choice in comparisons:
option_a = question['option_a']
option_b = question['option_b']
utility_a = w_retention * option_a['retention'] - w_time * option_a['time_minutes']/60
utility_b = w_retention * option_b['retention'] - w_time * option_b['time_minutes']/60
# Logistic model of choice probability
prob_choose_a = 1 / (1 + np.exp(-(utility_a - utility_b)))
if choice == 'A':
error += -np.log(max(prob_choose_a, 1e-10))
else:
error += -np.log(max(1 - prob_choose_a, 1e-10))
return error
# Constrain weights to sum to 1
constraints = {'type': 'eq', 'fun': lambda w: w[0] + w[1] - 1}
bounds = [(0.01, 0.99), (0.01, 0.99)]
try:
result = minimize(objective, [0.5, 0.5], bounds=bounds, constraints=constraints)
return tuple(result.x)
except Exception:
# Fallback if optimization fails
return (0.6, 0.4)
def pairwise_comparison_elicitation(self) -> Tuple[float, float]:
"""Elicit weights through pairwise comparisons"""
scenarios = [
{"retention": 0.90, "time_minutes": 20},
{"retention": 0.85, "time_minutes": 15},
{"retention": 0.95, "time_minutes": 30},
{"retention": 0.92, "time_minutes": 25},
{"retention": 0.88, "time_minutes": 18}]
comparisons = []
# Generate strategic pairs (not all combinations)
strategic_pairs = [
(0, 1), # 90% @ 20min vs 85% @ 15min
(2, 3), # 95% @ 30min vs 92% @ 25min
(1, 4), # 85% @ 15min vs 88% @ 18min
(0, 3), # 90% @ 20min vs 92% @ 25min
(1, 2)] # 85% @ 15min vs 95% @ 30min
print("I'll show you 5 pairs of Anki scenarios. Please choose your preference for each.")
for i, j in strategic_pairs:
question = {
'type': 'pairwise',
'option_a': scenarios[i],
'option_b': scenarios[j]}
choice = self.ask_human(question)
comparisons.append((question, choice))
return self.fit_utility_weights_from_pairwise(comparisons)
def direct_tradeoff_elicitation(self) -> Tuple[float, float]:
"""Elicit weights through direct trade-off questions"""
print("\nNow I'll ask about specific trade-offs...")
questions = [
{
'type': 'tradeoff',
'question': "You currently have 90% retention at 25 minutes/day.\nWhat's the minimum retention you'd accept to reduce time to 20 min/day? (enter percentage, e.g., 85)",
'min_value': 70,
'max_value': 90
},
{
'type': 'tradeoff',
'question': "What's the maximum time per day you'd spend to increase retention from 90% to 95%? (enter minutes)",
'min_value': 25,
'max_value': 60
},
{
'type': 'tradeoff',
'question': "At what retention level would 15 min/day be equally attractive as 90% retention at 25 min/day? (enter percentage)",
'min_value': 70,
'max_value': 90
}]
answers = []
for q in questions:
answer = float(self.ask_human(q))
answers.append(answer)
return self.calculate_weights_from_tradeoffs(answers)
def swing_weight_elicitation(self) -> Tuple[float, float]:
"""Elicit weights using swing weight method"""
print("\nFinal question: Imagine the worst-case scenario: 80% retention at 45 min/day")
print("You can make exactly ONE improvement:")
question = {
'type': 'pairwise',
'option_a': {'retention': 0.95, 'time_minutes': 45}, # Improve retention
'option_b': {'retention': 0.80, 'time_minutes': 15}} # Improve time
choice = self.ask_human(question)
# Follow-up quantification
if choice == 'A':
follow_up = {
'type': 'tradeoff',
'question': "You chose better retention. On a scale 0-100, how much would you pay to ALSO get the time improvement?",
'min_value': 0,
'max_value': 100}
ratio = float(self.ask_human(follow_up))
w_retention, w_time = 100, ratio
else:
follow_up = {
'type': 'tradeoff',
'question': "You chose better time. On a scale 0-100, how much would you pay to ALSO get the retention improvement?",
'min_value': 0,
'max_value': 100}
ratio = float(self.ask_human(follow_up))
w_time, w_retention = 100, ratio
# Normalize
total = w_retention + w_time
return w_retention/total, w_time/total
def calculate_consistency(self, weight_sets: List[Tuple[float, float]]) -> float:
"""Calculate consistency score across different elicitation methods"""
if len(weight_sets) < 2:
return 1.0
weights_array = np.array(weight_sets)
# Calculate coefficient of variation for each weight
mean_weights = np.mean(weights_array, axis=0)
std_weights = np.std(weights_array, axis=0)
# Avoid division by zero
cv = np.where(mean_weights > 0, std_weights / mean_weights, 0)
# Convert to consistency score (1 = perfectly consistent, 0 = completely inconsistent)
consistency = 1 - np.mean(cv)
return max(0, consistency)
def comprehensive_weight_elicitation(self) -> Tuple[float, float]:
"""Main function combining all elicitation methods"""
print("=== Anki Weight Elicitation ===")
print("I'll help you determine how much you value retention vs. time savings.")
print("This will take about 10 minutes.\n")
# Method 1: Pairwise comparisons
print("STEP 1: Pairwise Comparisons")
weights_pairwise = self.pairwise_comparison_elicitation()
print(f"Pairwise method suggests: {weights_pairwise[0]:.2f} retention, {weights_pairwise[1]:.2f} time")
# Method 2: Direct trade-offs
print("\nSTEP 2: Direct Trade-offs")
weights_tradeoff = self.direct_tradeoff_elicitation()
print(f"Trade-off method suggests: {weights_tradeoff[0]:.2f} retention, {weights_tradeoff[1]:.2f} time")
# Method 3: Swing weights
print("\nSTEP 3: Swing Weights")
weights_swing = self.swing_weight_elicitation()
print(f"Swing weight method suggests: {weights_swing[0]:.2f} retention, {weights_swing[1]:.2f} time")
# Check consistency
all_weights = [weights_pairwise, weights_tradeoff, weights_swing]
consistency_score = self.calculate_consistency(all_weights)
print(f"\nConsistency score: {consistency_score:.2f} (1.0 = perfectly consistent)")
if consistency_score < 0.7:
print("Inconsistent responses detected. Let me help clarify...")
weights_final = self.resolve_inconsistencies()
else:
# Weighted average based on method reliability
weights_final = (
0.4 * np.array(weights_pairwise) + # Most reliable
0.35 * np.array(weights_tradeoff) + # Good for ratios
0.25 * np.array(weights_swing)) # Good for extremes
weights_final = tuple(weights_final)
# Validation
print("\nSTEP 4: Validation")
validation_question = self.generate_validation_scenario()
predicted_choice = self.predict_choice(validation_question, weights_final)
actual_choice = self.ask_human(validation_question)
if predicted_choice != actual_choice:
print("Let me refine the weights based on your response...")
weights_final = self.refine_weights(weights_final, validation_question, actual_choice)
else:
print("Great! The weights accurately predict your preferences.")
print("\nFINAL WEIGHTS:")
print(f"Retention importance: {weights_final[0]:.3f}")
print(f"Time importance: {weights_final[1]:.3f}")
print(f"\nInterpretation: You value 1% retention gain equally to {weights_final[1]/weights_final[0]*60:.1f} minutes saved per day.")
return weights_final
def main():
# Your data
x = [70, 73, 76, 79, 82, 85, 88, 91, 94, 97] # DR percentages
y = [19.8, 22.6, 26.2, 31.1, 37.1, 45, 57.2, 76.2, 114.5, 230.3] # minutes per day
elicitor = AnkiWeightElicitor()
w_retention, w_time = elicitor.comprehensive_weight_elicitation()
print("=== Anki DR Optimization Results ===")
print(f"Your weights: Retention = {w_retention:.3f}, Time = {w_time:.3f}")
print(f"Interpretation: You value 1% retention gain equally to {w_time/w_retention:.1f} minutes saved per day")
print()
# Initialize optimizer
optimizer = DROptimizer(x, y)
# Simple optimization
optimal_dr_simple, optimal_utility_simple = optimizer.simple_optimization(w_retention, w_time)
optimal_time_simple = optimizer.get_time_for_dr(optimal_dr_simple)
print("=== SIMPLE OPTIMIZATION ===")
print(f"Optimal DR: {optimal_dr_simple*100:.1f}%")
print(f"Expected time: {optimal_time_simple:.1f} minutes/day")
print(f"Utility score: {optimal_utility_simple:.3f}")
print()
# Robust optimization
optimal_dr_robust, optimal_utility_robust = optimizer.robust_maut_optimization(w_retention, w_time)
optimal_time_robust = optimizer.get_time_for_dr(optimal_dr_robust)
print("=== ROBUST OPTIMIZATION ===")
print(f"Optimal DR: {optimal_dr_robust*100:.1f}%")
print(f"Expected time: {optimal_time_robust:.1f} minutes/day")
print(f"Robust utility score: {optimal_utility_robust:.3f}")
print()
# Compare with your current data points
print("=== COMPARISON WITH YOUR DATA POINTS ===")
print("DR% | Time(min) | Utility")
print("-" * 30)
for dr_pct, time_min in zip(x, y):
dr = dr_pct / 100.0
utility = optimizer.overall_utility(dr, w_retention, w_time)
marker = " ← OPTIMAL" if abs(dr - optimal_dr_simple) < 0.01 else ""
print(f"{dr_pct:3d} | {time_min:8.1f} | {utility:7.3f}{marker}")
print()
# Sensitivity analysis
print("=== SENSITIVITY ANALYSIS ===")
print("How much utility you lose by deviating from optimal:")
optimal_utility = optimizer.overall_utility(optimal_dr_simple, w_retention, w_time)
for dr_pct in [70, 75, 80, 85, 90, 95]:
dr = dr_pct / 100.0
utility = optimizer.overall_utility(dr, w_retention, w_time)
utility_loss = optimal_utility - utility
utility_loss_pct = (utility_loss / abs(optimal_utility)) * 100
time_at_dr = optimizer.get_time_for_dr(dr)
print(f"DR {dr_pct}%: {time_at_dr:.1f} min/day, utility loss = {utility_loss_pct:.1f}%")
# Create visualization
print("\nGenerating plots...")
optimizer.plot_analysis(w_retention, w_time, optimal_dr_simple)
# Practical recommendation
print("\n=== PRACTICAL RECOMMENDATION ===")
# Find closest available DR
available_drs = np.array(x) / 100.0
closest_idx = np.argmin(np.abs(available_drs - optimal_dr_simple))
recommended_dr = x[closest_idx]
recommended_time = y[closest_idx]
print("Since you can only choose from your tested values:")
print(f"RECOMMENDED DR: {recommended_dr}%")
print(f"Expected time: {recommended_time:.1f} minutes/day")
# Show cost of suboptimal choices
print("\nCost of other choices:")
for i, (dr_pct, time_min) in enumerate(zip(x, y)):
if dr_pct != recommended_dr:
time_diff = time_min - recommended_time
if time_diff > 0:
print(f"DR {dr_pct}%: +{time_diff:.1f} min/day ({time_diff*7:.0f} min/week extra)")
else:
print(f"DR {dr_pct}%: {time_diff:.1f} min/day (saves {-time_diff*7:.0f} min/week)")
if __name__ == "__main__":
main()