Let’s be absolutely clear:
If the distribution of card difficulties in your dataset is broken, you’re cutting the legs out from under the whole model even if you think you don’t “use” difficulty directly for optimization.
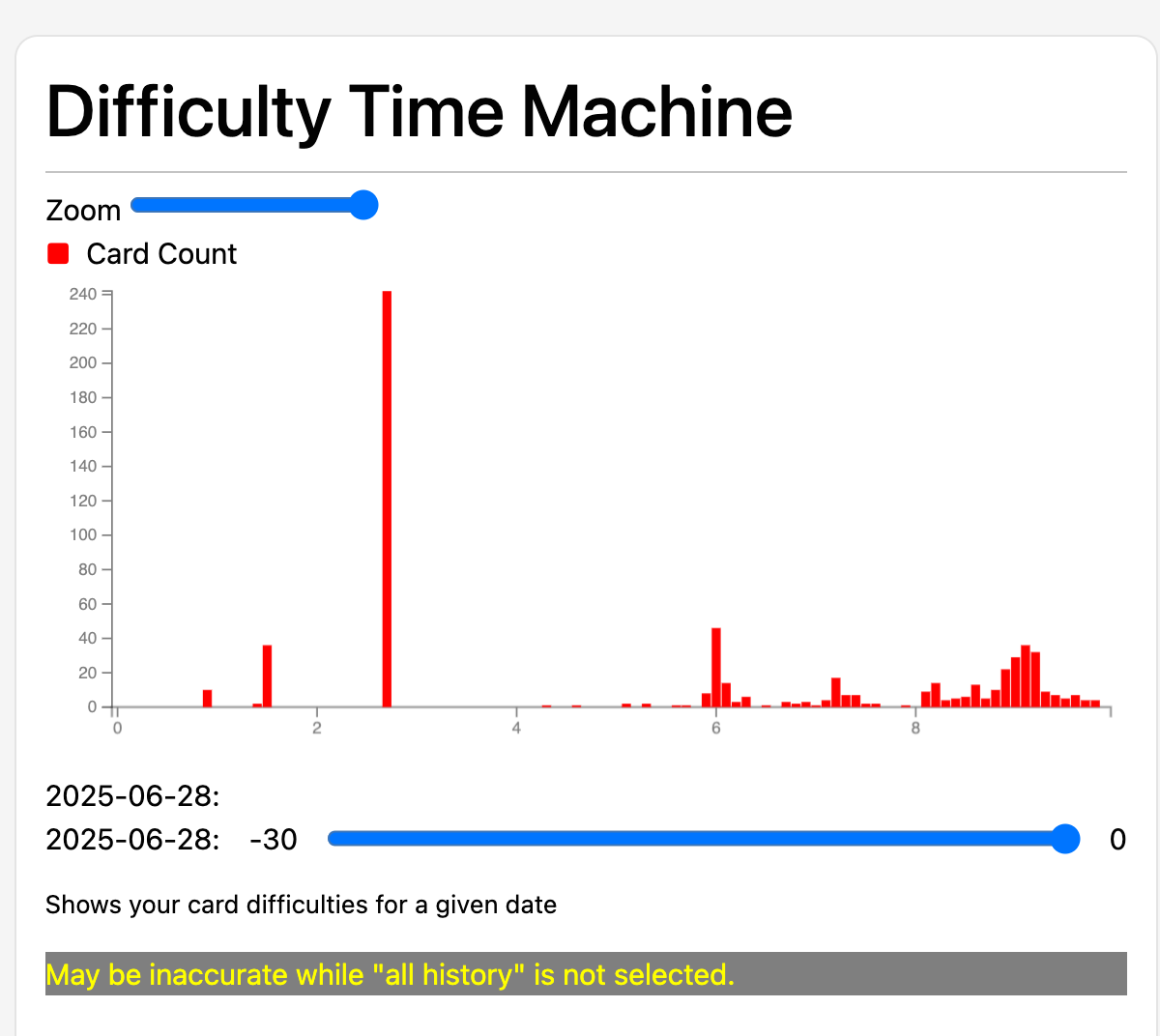
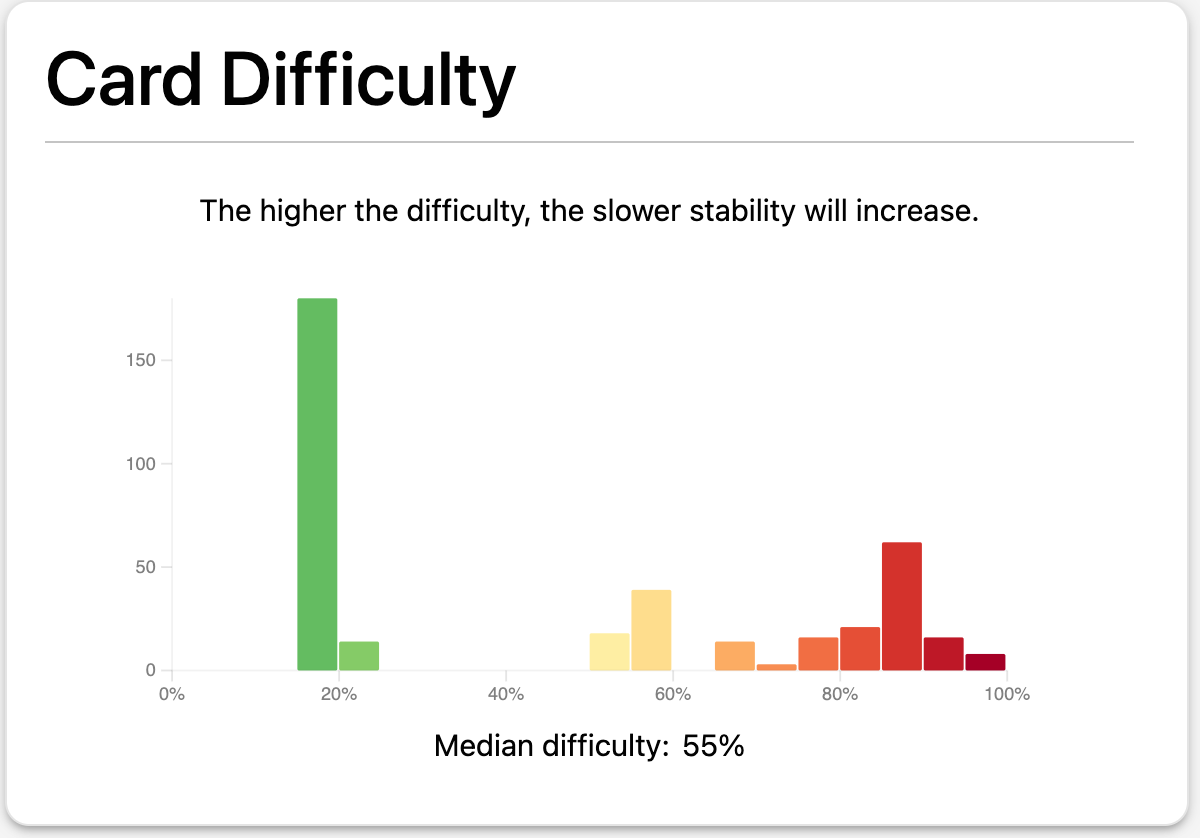
Difficulty isn’t some cosmetic field: it’s a core input at every review, driving the update of stability and, therefore, the entire scheduling process. If your dataset collapses difficulty into clusters say, hundreds of cards stuck at 10 from early training phases, and others at much lower levels then your optimizer is working with fundamentally corrupted data. No amount of parameter tuning will patch over a distribution that doesn’t reflect the reality of the learner’s experience.
Frankly, it’s absurd to ignore this structural flaw.
When you optimize FSRS on a real dataset, you’re not just fitting parameters to a static world; you’re managing a dynamic system of latent variables. If you don’t recalculate the full trajectory of card difficulties when you update parameters, you’re literally training on a dataset polluted by outdated, sometimes completely wrong, difficulty estimates. Over time, this leads to catastrophic effects: clusters of cards “stuck” at high difficulty (typically from early phases when the system wasn’t in equilibrium) never normalize as more cards are added. The result is blocks of medium and maximum difficulty cards, and an optimizer that can only patch around the mess.
This isn’t just an academic detail. It neuters the optimizer. You end up with a pseudo-stable system, where hundreds of cards sit at difficulty 10 for months or years totally disconnected from reality. It destroys both learning speed and interpretability.
What’s needed is a hardcore, bi-level optimizer one that, when needed, can recursively update all card difficulties using the full review history and the current parameter set. Yes, it’s more computationally demanding, but you only need to run it occasionally to “reset” the system and clean up the latent space. Once that’s done, normal FSRS operation can resume as usual.
Bottom line:
This is a dynamic system, not a static snapshot. Optimizing the loss at a single point in time is fundamentally broken if you don’t update the latent beliefs. If you care about the long-term health and speed of your scheduling, you cannot ignore this. The marginal gain in model integrity is massive.