Your method sounds a little complex. Is there a reason why cards in your deck must have a random order for their unique identifier?
Anyway, as long as it works! Having a unique identifier for each note is a key to greater usability I believe.
I could have tried using commas, but the way I work is:
- The master file is an Excel file that I locally update
- When I save it, I automatically export it to TXT, formatted for Anki
- I import that into Anki.
- I finally export Anki’s deck as TXT
- I automatically fetch the downloaded TXT’s contents and insert it in the Excel sheet
Since I directly read and ingest TXT and Excel files, I wanted to make sure no issue could appear by dealing with commas instead of tabs. It also makes it a bit easier to open the resulting TXT file with a notepad reader and get an idea of how things look like (if needed, e.g. for debugging the script that produces the TXT)
Anki provides a randomly-generated 10-character string (alphanumeric+characters) to its notes. I realized this when I exported my deck, before I realized I had to maintain the GUIDs myself.
I simply copied Anki’s method.
Also, by doing so, I avoid any potential problem that could arise when deleting a note: deleting a note would mean removing a row from my spreadsheet, how do you ensure that the row that came next doesn’t get its identifier changed if you use Excel’s logic of dragging the first column along an incremental value?
Also, by working with random identifiers, I do not need to keep track of potential overlaps: the GUID generating script needs to generate a random GUID and simply make sure it didn’t get used before (by simply checking the previous GUIDs). In total, I get almost 100 different characters, so 100^10 different possibilities: it’s very, very unlikely that a randomly generated GUID matches a previously generated one, but even that case is covered.
When I first create a deck, I drag down the formula calculating the GUID. Any new cards added, are added to the end of the data in the spreadsheet, and so I can continue to drag.
On the rare occasions where I must delete a card, I follow one of two processes.
- Just delete the row and that means that the unique identifier is never used.
- I delete the data associated with the row and just place a row of new data into that line, thus preserving the unique identifier, but repurposing it.
Both methods work fine and have caused no issues with my decks. There are a couple of thousand users of my decks, I think, in total, so they are reasonably well tested.
I see a problem with your first and second process concerning deletion:
-
If you delete the row from your spreadsheet, how do you make sure it gets deleted from Anki?
-
If you repurpose the identifier, any data the note has in Anki concerning the stage it is in your learning and what the repetition steps are are also inherited, which is not ideal.
The main reason I work with random identifiers is to avoid any such problem and also avoid the need to keep track of any identifier overall: I just simply tag the note for deletion on Excel, export the TXT, import it into Anki, delete the note with the deletion tag, export the deck from Anki as TXT, ingest it into Excel, and the old note is gone without me having to care about an empty row or how to manage it and its identifier.
Thanks! I forgot to mention that I also delete the record from Anki before uploading. That way there is no confusion.
I should add that of the tens of thousands of cards I have created, I have only ever had to delete three times. It is a very rare occurrence for me. So rare that I do not feel the need to automate it better.
But as I said before, if you method works well for you, that is great!
By the way, any chance of sharing your Python script that we might learn from you?
@Rumo mind taking a look at this when you have a chance?
Find here the repository with all my files:
This is the solution I have envisioned for managing Anki with XLS files
1 Like
Thank you! I didn’t realise that you were using pandas.
It looks very interesting. I am not running Windows, so may have to tweak things, but it looks very interesting! Thank you for sharing.
I am happy to contribute to the community ![]()
BTW, just for the sake of keeping this documented in this thread, I have been playing around and have noticed that Anki’s GUIDs must be unique across all decks, so Anki does not only compare them with the notes in the same deck for establishing a new note being equal to an existing note, but with all existing notes in all decks.
Thus, a quick way to overcome this is by adding a prefix to the GUID that identifies the deck. The code has been updated on GitHub.
1 Like
Anki is updating an existing note with the CSV row without a GUID because you have selected Update. You want to choose Duplicate instead.
You may run into limitations as you cannot choose a different setting for rows with and without a GUID. But in this case Anki should have you covered: it should update notes if there’s a GUID, and always add add a new one if there isn’t.
@matta has already pointed out that you can choose any separator you like as long as you (or your CSV writer) quotes fields correctly. I just want to add that you still might need to add quotes when separating with tabs, e.g. if a row starts witht a # (which is possible in GUIDs).
Finally, I would be careful when generating your own GUIDs. These are not just random strings, but encoded 64-bit integers. I’m not aware Anki is trying to decode or assigning semantics to them anywhere, but I’m not 100% sure. There have already been issues with users or add-ons generating their own IDs.
Also, GUIDs are meant to be unique globally, i.e. across all collections. That’s virtually a given with random 64-bit integers, but entropy may be drastically lower depending on how you generate those strings.
@dae, sorry for the late reply. Were you referring to anything in particular?
1 Like
The option Duplicate does not seem to work.
I’m retaking my previous test deck with the following notes:
#separator:tab
#html:false
#guid column:1
#tags column:3
"o@6*#i~7sV" key1 val1
Q=tnka&&Vx key2 val2
The GUIDs for those 2 notes have been generated by Anki, not by me: I get that TXT when exporting the test deck with the 2 notes.
Let’s now change the text so that one note has now a different key and the other one a different value:
#separator:tab
#html:false
#guid column:1
#tags column:3
"o@6*#i~7sV" key100 val1
Q=tnka&&Vx key35 val2
Let me try to import that into the test deck in Anki:
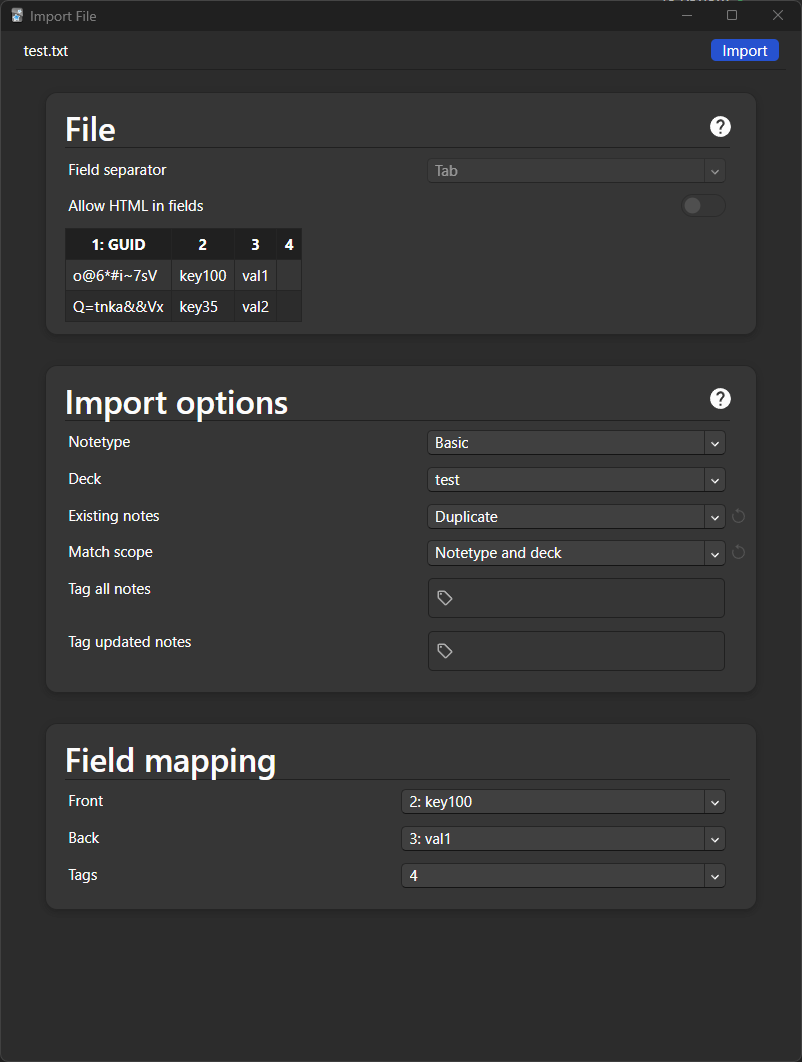
And here comes the issue: the note are skipped, not updated:

Thus, the only way forward is with Update, as I showed in my previous example.
Concerning a GUID containing a #, I am escaping that whole GUID with quotation marks in Excel. I could also just simply avoid the # when generating random GUIDs in my code, either way is anyways fine.
So far, I have not had any issues with generating my own GUIDs: when I export a TXT file from Anki, the GUIDs it generates do not seem to be parsed in any different way than mine. In order to make sure they are unique with respect to all decks, I simply add a prefix that identifies the deck when generating them (see my code).
That ship has sailed - third-party generators are making their own GUIDs, so if we ever try to convert them to integers, we’ll need to do something like hashing values that aren’t in Anki’s native format.
Falling back to matching on first field when a GUID is empty but provided feels a bit surprising - was that intentional?
GUIDs need to be unique, so it’s not clear what ‘duplicate’ would do here, since you’ve provided a GUID already.
Note that I wrote:
@dae, yes it was deliberate. There is no distinction between an empty and a missing GUID. The CSV parser knows whether a file has a GUID column or not, but the importer looks more or less at individual notes.
It would be possible for the parser to pass an option like ‘Match first field’ to the importer. But I think the current implementation covers more use cases:
- In @jae-joong’s case, rows with GUIDs are updates and rows without are insertions. This is currently supported by the Duplicate strategy.
- In other cases, it may just be that some rows are managed via GUIDs and some are not (because they come from another source or have an ID field). The Update strategy supports this.
Maybe we could expand the help text on how these settings relate to rows with GUIDs? Or is that too niche?
Thanks for clarifying. We could also update the help text, but for now, I’ve pushed a change to the manual that mentions how duplicates are not created in this case.
Please check the example I posted before with the test deck trying out the Duplicate option: it doesn’t work when changing fields in an existing card with a GUID, as Anki simply omits the notes as if they were already existing, even when the intention is to update them, hence why I keep using Update
Sorry, apparently I misremembered.
Having thought about it, the only reasonable action for notes with an existing GUID seems to be Update. So I guess we should ignore the Existing notes setting and just do that.
1 Like
I wonder if users would ever want to ignore existing GUIDs instead? Such as when they’ve made local edits, and want to only import new material from someone else, where that content has GUIDs. Might be rare though.
Hmmm, I struggle to see how that would make sense.
At the end of the day, if one makes local edits to the spreadsheet, it has to get synced to Anki - also, the moment one exports the deck from Anki as txt for further local edits, one would lose the local changes that got made.
Furthermore, if one gets any txt material from someone else that has GUIDs, I would say the best way forward is to delete said GUIDs from the txt file, which is very easy using a spreadsheet software like excel (just highlight that column and delete all values). Keeping the old GUIDs would anyway only cause potential issues, as they might be repeated within one’s notes across all decks.
1 Like