For example,
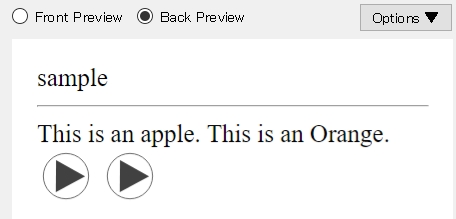
Eventually, 2 audio files would like to be generated as in image-2.
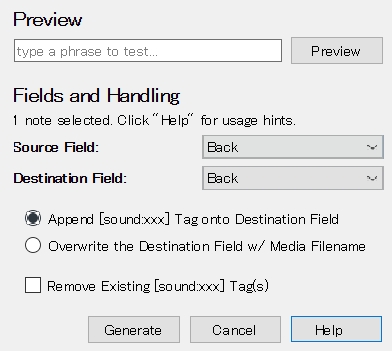
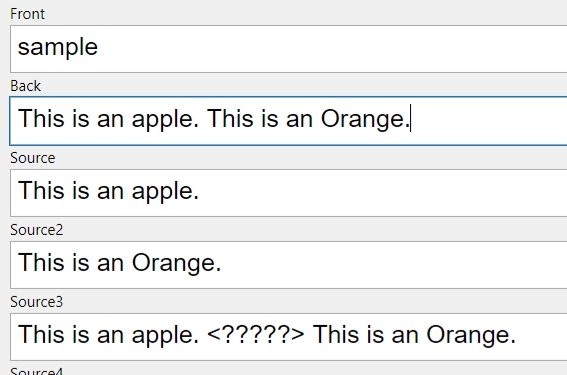
Though currently 2 actions are required as in image-4 and 5, do it single(1) action as in image-3 (ex) by including some delimiters as in image-1 (source3 filed)
Thank you for your continued support.
With the purpose of compatibility and quality, I would like to call precompiled audio file (google TTS), but anki TTS. Could you give me additional support for creating more than 2 audio files from 1 field (example above) by using (ex) awesome TTS.
Could anyone who have extensive familiarity with awesome TTS advise me (or inform me some workaround) how to create more than two audio files from 1 source filed (detailed explanation (what would like to do) described above)?
I use multiple audio notes in my cards made from Awesome TTS. I don’t know of any way to limit the audio generation so that it only occurs up to a certain point in the sentence. It may be possible with advanced TTS knowledge and using one of the advanced TTS services (Amazon? Azure?). To my knowledge, the audio file will generate speech for the entirety of the text that is sent.
What you want to do seems unnecessarily complicated… I have to ask what is the purpose of this? Why do you not want to use a single voice in generating the entire text field? Why do you want the text field broken into multiple voices?
This is the closest solution I can think of to approach what you want. In your example, why not create ‘Source1_audio’ and ‘Source2_audio’ fields, then in the cards you input those sound fields? That’s what I do.
Then in the card, you format…
{{source_text1}}{{source_text2}}{{source_audio1}}{{source_audio2}}
You would have to manually create source_audio1 and source_audio2 separately, but to be honest I think that is a trivial matter if you batch generate all of your audio files. You would also have to be doing this anyway if you’re wanting to use different TTS voices for the different sentence fragments within a card. Not sure if I understand what you are trying to do correctly…