That was basically what I intended, which was to give decks their own separate presets so that a more difficult deck does not share presets with a much easier deck. That is my absolute main concern. I cannot move individual cards because they are cloze cards and they all belong to their cloze notes.
Could you further elaborate
Cards of the same note can be in different decks.
Cloze notes are difficult for MorphMan-like add-ons though.
It is not about the “can” it is about that I wouldn’t. It would remove the context, behind the cloze cards and would do more damage than good.
Well, you already have too many decks, so I won’t suggest that you split them. That makes Anki slow. I have about 228.
Yes, my problem is that I have split the decks too much. I need to combine presets but I am afraid of two things:
1-I don’t know what threshold there is that balances out the number of cards and the number of presets.
2-I am afraid that difficult cards would be getting easier intervals and vice versa for easier cards.
Apparently, the method is not working.
Preset 1:
Log loss: 0.214, RMSE(bins): 4.03%. 10,414 reviews
Preset 2:
Log loss: 0.4262, RMSE(bins): 4.59% 6,423 reviews
Combined preset:
Log loss: 0.2840, RMSE(bins): 3.41%
I separate the presets but leave them the FSRS parameters of the combined one:
Log loss: 0.220, RMSE(bins): 4.01%
Log loss: 0.4314 RMSE(bins): 5.23%.
It would be interesting to look at presets with closer Logloss and RMSE.
I don’t see a problem.
Log loss: 0.214, RMSE(bins): 4.03% > Log loss: 0.220, RMSE(bins): 4.01%
Log loss: 0.4262, RMSE(bins): 4.59% > Log loss: 0.4314 RMSE(bins): 5.23%.
It doesn’t look like an improvement.
Ah, I see.
I’ll just wait for the benchmark on the new dataset, with deck and preset IDs, and see what that tells us. I think without that data we are just fumbling around.
Jarrett said it will be done in two weeks.
However, now that you pointed this phenomenon out - that RMSE of the combined preset can be better even if its parameters are worse for each preset individually - I’m afraid even with the new data I won’t be able to determine whether splitting decks/presets is good or bad.
The more I think about it, the more I feel like your discovery makes it nigh impossible to tell how much splitting is good.
So what do you suggest I do until then (since I cannot split decks further anymore than they are already)?
Do you think that my having set a single preset for entire subjects (main decks which are about 7000 cards in size on average) is a sensible alternative to what I was doing (preset for every single chapter deck)
Do you think that my having set a single preset for entire subjects … is a sensible alternative to what I was doing
Probably, but again, without the new data I don’t know.
RMSE has a strange (for me) tendency to decrease as the number of reviews increases. The same cannot be said about Log loss.

* - the entire collection.
Log loss is strongly correlated with retention, RMSE with the number of reviews. I knew it already, I just didn’t realize that it could lead to this.
Here’s a graph of RMSE as a function of N reviews, with a “trendline”.

Perhaps I could use it to calculate RMSE relative to the trendline. This could help to find the optimal number of decks/presets.
(also, before someone asks - yes, there are people with >1,400,000 reviews, you are reading the X axis right)
Is it only the number of reviews that matters, or does the number of cards also have any effect on this? I mean, if there are different numbers of cards for the same number of reviews.
No clue
Is the underlying issue here the optimizer overfitting? Does the optimizer have some regularisation applied, e.g. to discourage large diffs in parameters from the defaults (which I guess are found by optimizing over some very large composite set of review histories)?
If regularisation doesn’t exist, it probably should and may alleviate this kind of issue. The regularisation weight(s) should probably be determined by running some grid search, finding what minimises cross validation loss when optimizing different subsets of the large review dataset (eg optimizing single user review histories).
Whatever findings that come out of simulating presets and number of decks and cards and their RMSE values, I think this may have the biggest influence over RMSE values amongst all the other changes to FSRS recently thus far.
The first 4 parameters have L1 regularization, they are estimated differently compared to the rest.
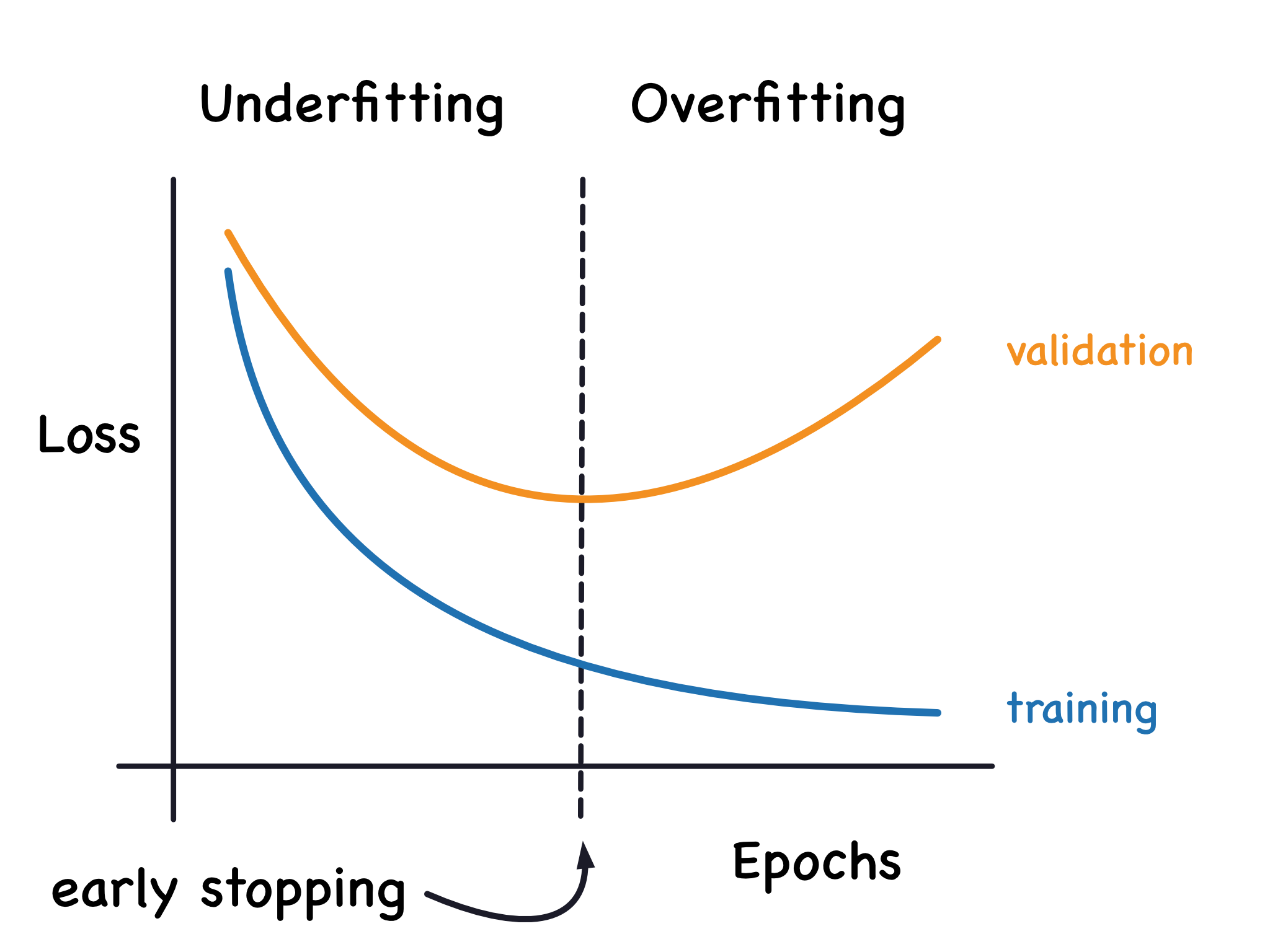
But no, I don’t think overfitting is an issue here. I’ve never observed the classic overfitting pattern when using the Google Colab optimizer, and I’ve used it a lot.
Plus, the way we calculate the final loss (and the final parameters) is similar to early stopping, so even if I did observe this pattern, I wouldn’t have to worry.
That was actually one of my first contributions (way before FSRS was integrated into Anki) - I told Jarrett to use parameters that correspond to the lowest weighted average of test loss and train loss, rather than just parameters from the last epoch.
What happens if we separate Parameters from presets? - A mechanism to make presets “choose” cards that are similar to each other and then build parameters based on these cards’ reviews. I don’t see why params have to be restricted to presets in the first place.