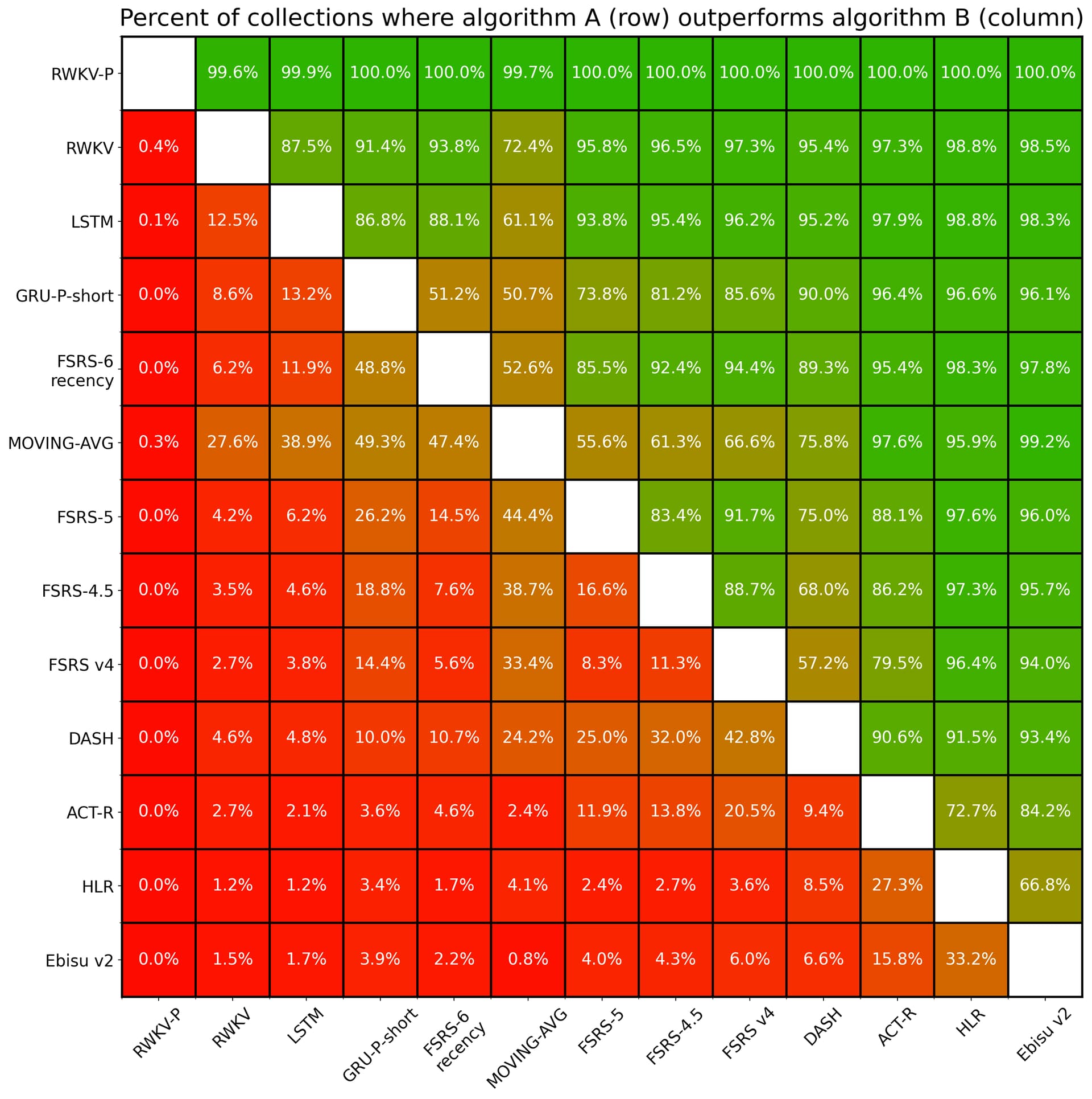
When we release a new version of FSRS, we always make sure that it’s better for >=51% of users, in the sense that if there is FSRS-X and FSRS-(X+1), FSRS-(X+1) should have lower logloss (a measure of how well the algorithm is predicting the probability of recall) for at least 51% of users in the 10k dataset.
For example, FSRS-6 with recency weighting (adapting more to newer reviews and less to older reviews) outperforms FSRS-5 for 85.5% of users. Of course, we also check that the average logloss is better, to avoid a situation where a new version is slightly better for a lot of people but significantly worse for a few.